为 StarryOS 实现 readahead
1. 背景和动机
1.1 现有 IO 机制的性能瓶颈
在 StarryOS 原有的文件系统架构中,针对大文件顺序读取场景(Sequential Read),存 在以下三个层面的显著性能瓶颈:
1. 请求粒度过于细碎(Fine-grained I/O Submission)
StarryOS 的缺页处理机制(Page Fault Handler)默认采用“按需调页”策略,即应用程序 每访问一页(4KB),才触发一次底层的 I/O 请求。这种 逐页提交(Page-by-page Submission) 的方式没有利用块设备的批量处理能力。
对于 100MB 的文件读取,内核需要发起 25,600 次独立的 I/O 请求。这意味着文件系统 层与块设备驱动层之间存在数万次的函数调用与状态同步,造成了巨大的指令周期浪费。
2. 软硬交互开销巨大 (Excessive Hardware Interaction Overhead)
在 RISC-V QEMU/VirtIO 等虚拟化环境下,驱动层与设备的交互成本极高。每一次独立的 I/O 提交都需要执行 MMIO 写操作(Doorbell Kick)以通知设备,并产生一次硬件中断 (Interrupt)以通知完成。
Warning
StarryOS 还没有实现 interrupt IO
后果:在逐页读取模式下,频繁的 MMIO 操作会导致大量的 VM-Exit(虚拟机陷入), Host 与 Guest 之间的上下文切换开销甚至可能超过了数据拷贝本身的耗时。这导致 CPU 在处理大量微小请求时陷入“颠簸(Thrashing)”状态。
3. 串行化 I/O 模型导致的流水线停顿 (Pipeline Stalls in Serial I/O)
原有的 I/O 处理路径是严格串行的“请求-等待-处理”模型。缺乏预取机制意味着数据请求 总是“被动”且“滞后”的。当应用程序处理当前数据页时,存储设备处于闲置状态;当应用 程序需要下一页数据时,必须发起新的 I/O 请求并等待数据到位。
后果:这种 “Stop-and-Wait” 模式无法利用 DMA(直接内存访问)的并行传输能力。CPU 的计算任务与 I/O 设备的数据传输任务在时间轴上互斥,导致系统无法建立有效的处理流 水线,I/O 延迟完全暴露在关键路径上。
1.2 预读机制的必要性与理论基础
在操作系统设计中,I/O 子系统的性能直接决定了数据密集型应用的执行效率。引入异步 预读(Asynchronous Readahead)机制并非单纯的功能堆砌,而是为了解决计算机体系结 构中存在的几个根本性矛盾。
1. 弥合 CPU 与存储设备的速度鸿沟 (Bridging the Speed Gap)
现代处理器的时钟频率通常在 GHz 级别(纳秒级周期),而存储设备(尤其是机械硬盘甚 至 NVMe SSD)的访问延迟通常在微秒甚至毫秒级别。两者之间存在着 3 到 6 个数量级的 速度差异。
无预读场景(同步阻塞):当应用程序发生缺页(Page Fault)时,CPU 被迫停止流水线, 等待磁盘数据。对于 CPU 而言,这相当于法拉利跑车在每一个红绿灯路口都要熄火等待一 分钟。
预读场景:通过预测访问模式,操作系统提前将数据从慢速磁盘搬运至高速内存(Page Cache)。当 CPU 需要数据时,直接从内存读取(命中 Cache),从而将 I/O 访问延迟从 毫秒级降低至纳秒级。
2. 实现计算与 I/O 的并行流水线 (Parallelism & Pipelining)
在同步读取模型中,系统处于 “计算——等待——计算——等待” 的串行模式(Stop-and-Wait)。 这种模式导致系统总线和 I/O 设备在 CPU 计算期间闲置,而在 I/O 传输期间 CPU 又闲 置,资源利用率极低。
预读机制的核心价值在于 掩盖延迟(Latency Hiding)。通过异步提交 I/O 请求:
- DMA(直接内存访问) 控制器负责在后台搬运数据。
- CPU 继续执行前台应用程序的计算逻辑。
这种 CPU 与 DMA 的物理并行,使得数据搬运的时间被有效的计算时间所“掩盖”,从而显 著提升了系统的整体吞吐量(Throughput)。
3. 摊薄 I/O 栈的固定开销 (Amortizing I/O Stack Overhead)
在 StarryOS 运行的 RISC-V 虚拟化环境(QEMU/VirtIO)中,发起一次 I/O 请求的固 定开销极其昂贵,主要包括:
- 软件层:系统调用上下文切换、VFS 路径解析、文件系统元数据查询。
- 驱动层:构建描述符链、内存屏障指令。
- 硬件层:MMIO 寄存器写入(导致 VM-Exit)、中断处理(导致流水线冲刷)。
如果采用按需调页(逐页读取),每读取 4KB 数据就要承担一次完整的固定开销,有效载 荷比(Payload Ratio) 极低。 将多个物理不连续的页面请求合并为一个大的 I/O 事务 (Transaction)。通过“批发”代替“零售”,极大地摊薄了每一次 I/O 操作的固定成本, 减少了昂贵的 MMIO 和中断次数。
4. 利用空间局部性原理 (Exploiting Spatial Locality)
绝大多数文件访问模式遵循空间局部性(Spatial Locality)原理,即一旦程序访问了文 件的某个位置,它很有可能在不久的将来访问其相邻的位置(如视频播放、日志分析、编 译器读取源码)。
预读机制正是基于这一原理,将大概率会被访问的数据提前加载。这不仅提升了缓存命中 率,还通过顺序 I/O 发挥了存储设备的最佳性能(减少机械磁盘的寻道时间或利用 SSD 的内部并行通道)。
2. 系统架构
2.1 StarrOS IO 读取架构图
对于从 ext4 磁盘读取文件的情景,StarryOS 的处理流程如下:
2.2 层级简要解释
系统调用层 (Syscall Layer)
为用户应用提供 read 系统调用, 解析文件描述符 fd 获取 FileLike trait object, 这里
践行了 Unix 的 "一切皆文件" 哲学, 在我们的情境下, FileLike 的实现由 Starry
api 的 file::fs::File VFS 包装器提供。
VFS 包装层 (VFS Wrapper)
为上层提供 FileLike trait 实现, 并适配 POSIX 语义(如阻塞/非阻塞 IO 处理), 将
调用转发给内部的 ArceOS 文件 axfs::File 对象。非阻塞 IO 比如 socket 和 pipe,
而对于磁盘文件则按阻塞 IO 处理。
ArceOS 文件系统层 (ArceOS VFS)
从实现了 FileNodeOps trait 的具体文件系统中读取数据, 写回用户请求提供的
buffer 中, 并提供了两种写回模式:
- Direct: 直接将数据写回用户空间 (user buffer)
- Cached: 将数据拷贝到内核空间 (page cache) 作为缓存, 再写回用户空间。
具体文件系统
在我们的情景下, 文件系统是 ext4。提供 FileNodeOps 实现, 将逻辑转发给
lwext4_rust 库。lwext4_rust 的工作如下:
- 解析 Ext4 文件系统结构(Inode, Extent Tree),计算逻辑偏移量对应的物理块号 (LBA)。
- 调用实现了
BlockDevice的块设备接口获取数据。
块设备适配层 (Block Device)
运用了依赖倒置原则, 在 axfs 中实现了 lwext4_rust 库中定义的 BlockDevice trait,
并最终将块读取请求转发到驱动层。
驱动层 (Driver Layer)
组件: AxBlockDevice (即 VirtIoBlk), axdriver 职责: 构建 VirtIO 请求,写入 VirtQueue,通知硬件(通过 MMIO 或 PCI 寄存器)。
3. 核心设计
我们的 readahead 工作集中在 ArceOS VFS 层, 优化了 Cached 模式的缓存管理策略以及 IO 请求策略, 按照如下的顺序依次递进:
- 启发式 readahead 窗口更新策略
- 聚合 IO 请求, 实现批量 IO 读取
- 引入 pending page, IO 读取任务重叠问题
3.1 启发式 (Heuristic) readahead 窗口更新
概览
我们借鉴了 Linux 的实现, 将预读的策略抽象为一个窗口, 窗口有五个状态:
- start
- size
- async_size
- prev_pn
- max_pages
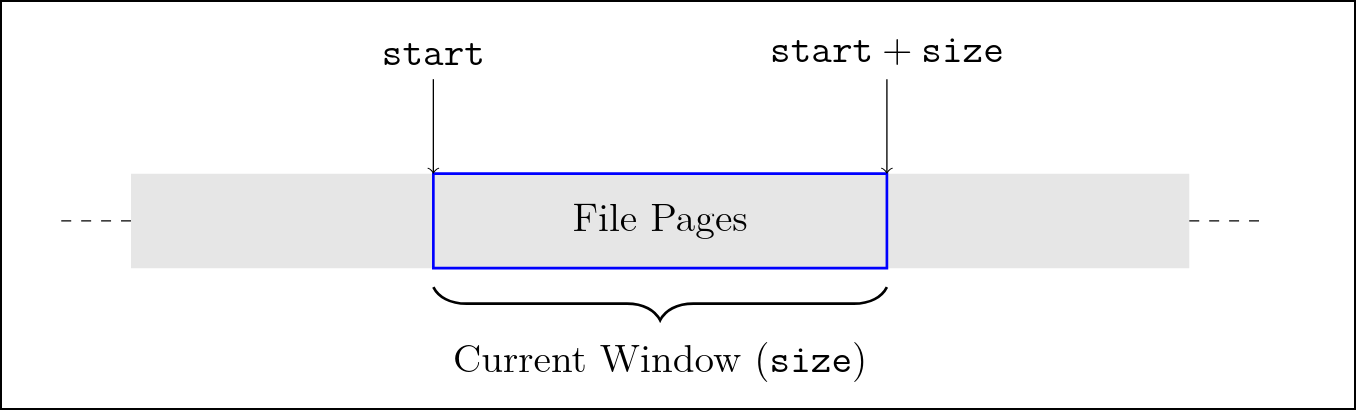
待读取文件按页大小 (这里是 4kib) 被分为一段页面序列, start 和 size 用于表示 预读窗口在这段页面序列中的位置, 页号从 start 开始, 长度为 size。
async_size 表示离窗口末尾, 也就是 start + size, 执行异步预读的距离。在我 们的预读窗口中, 往往会超过用户请求的窗口大小, 将一系列页面提前缓存到 page cache 池子中, 而 async_size 描述的就是发起异步预读的时机。具体来说, 当检测到用户的 读取请求来到了 start + size - async_size 位置的页面时, 表明用户的读取符合 我们的顺序读取预期, 此时会发起一个异步预读。这个特殊的页面被标记为 PG_readahead。
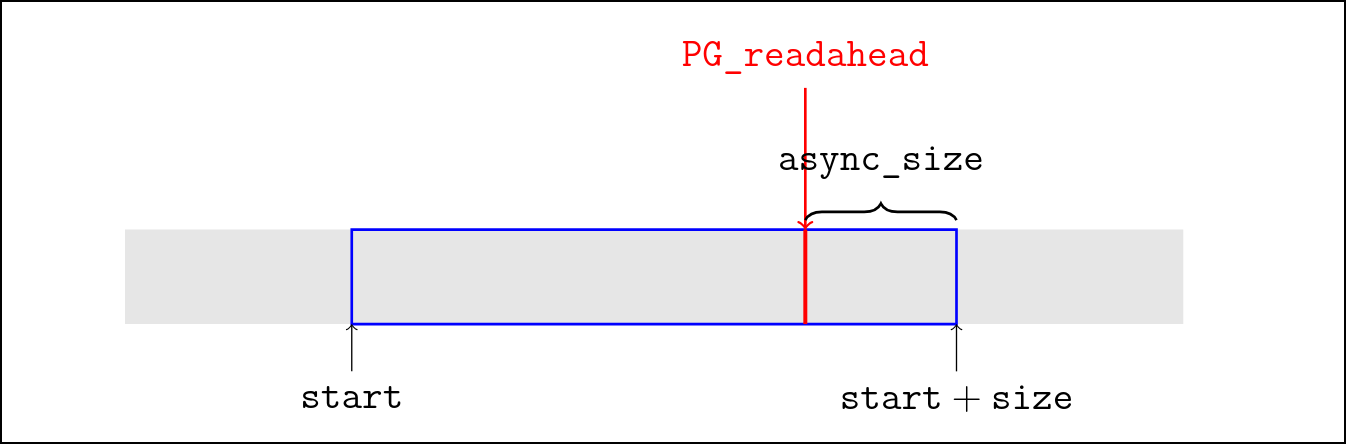
prev_pn 标记上一次用户请求的末尾页面, 这个状态用于对用户的请求的顺序性判断; 如果是顺序读取 (如前文所述, 大部分文件读取都遵循这个规律), 则正常执行预读; 如果 是随机读取 (常见于数据库), 则立刻关闭预读, 不作额外的缓存冗余, 以减小内存等浪费。
max_pages 限定了预读的窗口大小的最大值, 需要综合内存压力和 page cache 池大小 考量。
预读的触发有两种:
- 同步预读
- 异步预读
同步预读发生在 cache miss 时, 此时用户请求的数据没有在页缓存中, 为了响应用户的 请求, 我们必须阻塞的从 IO 设备中获取响应的数据, 然后返回给用户。而每一次 IO 请 求都有一定的开销, 比如软件应用栈, 还有硬件的开销, 比如磁盘寻道。因此在从 IO 设 备获取数据时, 我们获取了比用户实际请求的数据更多一些存放在内核空间的 page cache 中, 以便用户下一次顺序读取的时候可以直接从内存中获取数据。这就是同步预读。
异步预读发生在用户请求命中我们标记的 PG_readahead 页面时。此时用户的读取符合 我们对顺序读取的假设, 因此会立刻发起一个异步预读任务, 按流水线提前搬运下一批页 面到 page cache 中。此时前方还有数量为 async_size 的页面在 page cache 中, 供 用户消费。发起的异步预读任务与现在的 CPU 计算形成并行流水线。
example
下面我们来结合一个具体的顺序读取用户请求, 来详细说明处理的过程。在 sys_read 系 统调用中, 用户的请求是以字节为单位的, 为了表述方便, 下面的用户请求都转化为了以 页面为单位。
1. 初始化
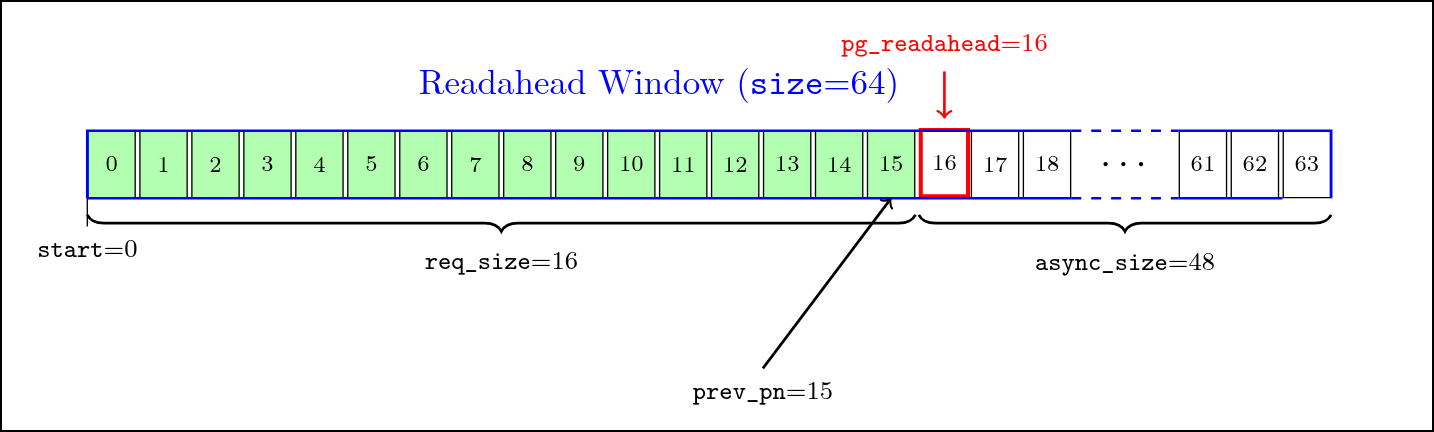
用户请求了从 0 开始, 长度 req_size 为 16 的数据, 由于是初次请求, page cache 中还没有任何缓存, 此时触发同步预读。我们会假定每个初次请求接下来会进行顺序读取, 因此将 req_size * 4 的数据请求提交给 IO 设备。此时 start 为 0, *size* 为 64。
而 async_size 被设置为了 size - req_size = 48, 即 pg_readahead 被设置在 了 start + size - async_size = 16 的位置, 也就是用户请求页面中最后一页的 下一页。这样开启了最激进的 full pipeline, 意味着用户再次请求下一个页面, 就会 遇到 pg_readahead, 判定为顺序读取, 发起异步预读。
将用户的请求处理完成后, 将 prev_pn 指向用户请求的最后一个页面, 也就是 15。
此时窗口的状态如下:
start: 0size: 64async_size: 48prev_pn: 15max_pages: MAX_PAGES 常量
2. 顺序读取
用户按照预期, 发起了从 16 开始, req_size 为 16 的请求。此时 page cache 中已经 拥有了我们需要的数据, 直接从内存获取数据并写回给用户。由于我们使用了 full pipeline, 在最开头的位置 (index = 16) 处设置了 pg_readahead, 此时触发了异步 预读, 在不阻塞处理用户接下来的请求的同时搬运数据。
窗口状态在遇到了 pg_readahead 的时候, 沿着流水线方向更新。start 设置为上一 个窗口的末尾后一页, size 为前一个窗口的大小 * 2, 直到达到 max_pages。 async_size 被设置为与新的 size 相同的大小, 即将新窗口的第一页标上 pg_readahead, 开启 *full pipeline*。
prev_pn 在每次处理完用户请求后更新为用户请求的最后一个页面。
此时窗口的状态如下:
start: 64size: 128async_size: 128prev_pn: 31
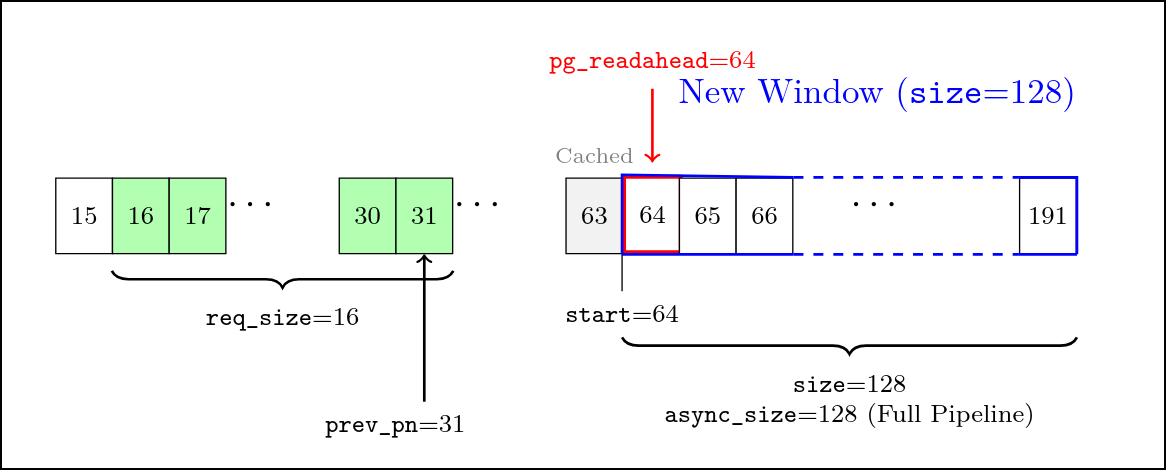
可以看到这次用户读取之后, 窗口跳跃到了用户实际请求窗口流水线的后面了, start 要比 prev_pn 更大了。但是这样仍然是可以正确工作的, 因为上一个窗口读取到的数据 依旧存在 page cache 中。在用户新的读取请求中, 从 prev_pn + 1 到 start 这一 段的数据仍旧可以命中缓存。不过这也对我们的 page cache 池提出了要求: 至少要能容 纳连续的两个窗口。
不过这其中的缓存可能会因为抖动被释放。此时为了不被误判为随机读取, 增强预读流水 线的鲁棒性, 从 prev_pn 到 start 发生的小概率 cache miss, 不会被判定为随机读 取从而关闭预读, 而是在 cache miss 处重建同步预读窗口, 开启新的流水线。
3. 稳定状态
由上文描述的逻辑可知, 在连续的顺序读取场景中, 最终窗口大小会生长到 max_pages,
同时每个窗口的第一页有 pg_readahead 标记。用户读取请求到了窗口起始位置后, 立
刻发起异步预读, 更新到下一个窗口。
3.2 聚合 IO 请求
问题分析
虽然我们引入了预读窗口机制,但在 StarryOS 的实现中,底层的 IO 提交策略仍然是“逐
页提交”。这意味着,如果预读窗口大小为 16 页(64KB),内核会发起 16 次独立的
file.read_at 调用。
如前文所述,在虚拟化环境下,每一次 IO 请求都伴随着昂贵的固定开销(上下文切换、 MMIO 陷阱、中断处理)。这种“零存整取”的策略虽然在逻辑上实现了预读,但在物理执行 上并没有利用块设备的批量传输优势,导致 CPU 依然消耗在大量的驱动交互上。
引入 Bounce Buffer
为了解决这个问题,我们需要将多个物理上不连续的页面请求,合并为一次物理连续的大 块 IO 请求。由于 StarryOS 的底层驱动接口目前不支持 Scatter-Gather I/O(即一次调 用传入多个不连续的缓冲区),我们引入了 Bounce Buffer(跳板缓冲区) 机制。
具体流程如下:
- 计算合并大小:统计预读窗口中需要读取的页面数量 $N$。
- 申请缓冲区:分配一个大小为 $N \times 4KB$ 的连续内存缓冲区(Bounce Buffer)。
- 批量读取:发起一次大小为 $N \times 4KB$ 的底层 IO 请求,将数据读入 Bounce Buffer。这一步只产生一次驱动交互开销。
- 数据分发:在内存中通过
memcpy,将 Bounce Buffer 中的数据分别拷贝到 Page Cache 的各个物理页面中。
虽然引入了额外的内存拷贝开销,但相比于昂贵的 VM-Exit 和硬件交互开销,内存拷贝的 成本几乎可以忽略不计。
缓冲区复用优化
在初步实现中,我们为每次预读任务动态分配 Vec<u8> 作为 Bounce Buffer。然而,频
繁的大内存分配与回收(Allocator Thrashing)带来了新的性能抖动。
为了进一步优化,我们将 Bounce Buffer 作为一个复用资源集成到了状态中, 通过复用缓 冲区,我们消除了内存分配器的开销。
局限性与未来展望
Bounce Buffer 本质上是一种“空间换时间”的折衷方案。最理想的方案是实现驱动层的 Scatter-Gather DMA 支持,即允许驱动直接将磁盘数据传输到多个物理不连续的物理 页中,从而实现真正的零拷贝预读。但这涉及到驱动接口的重大重构,因此目前作为未来 工作计划。
3.3 Pending Page 机制
竞态条件:流水线追尾
在实际运行中,我们发现了一个棘手的竞态条件。由于内存访问速度远快于磁盘 IO,用户 线程(消费者)的读取速度往往快于后台预读任务(生产者)的数据填充速度。
当用户线程“追上”了正在进行的异步预读窗口时,它会请求一个正在读取但尚未完成 的页面。在早期的实现中,Page Cache 中此时还没有该页面的有效数据(或者页面根本未 插入),导致系统判定为 Cache Miss,从而触发一次同步预读。
这就导致了重复 IO(Duplicate IO):同一个数据块,后台任务在读,前台线程也在 读。这不仅浪费了 IO 带宽,还引发了严重的锁竞争。
解决方案:占位与等待
为了解决这个问题,我们在页缓存状态中引入了 Pending Page(待定页) 概念。
新的机制如下:
- 提前占位(Reservation):异步预读任务在发起底层 IO 请求之前,先在
Page Cache 中插入对应的页面,并将其标记为
pending状态。 - 状态感知:当用户线程访问这些页面时,会命中 Page Cache,但发现页面处于
pending状态。 - 避免重复:用户线程识别出“数据已经在路上了”,因此不会发起新的 IO 请
求,而是进入等待状态(或轮询),直到
pending标志被清除。 - 完成通知:当后台 IO 完成数据填充后,清除
pending标志,数据变为可用。 并且通知正在等待此页面的线程。
通过这种机制,我们确保了对于同一个物理页面,无论有多少个并发的访问请求,底层只 会有一次物理 IO 操作,实现了同步流与异步流的完美协同。
4. 具体代码实现
4.1 StarryOS 现有基础设施以及集成策略
CachedFile 的数据结构组成如下:
pub struct CachedFile {
inner: Location,
shared: Arc<CachedFileShared>,
in_memory: bool,
append_lock: RwLock<()>,
}inner: 底层 VFS 节点的位置句柄, 提供对底层文件系统的直接访问能力。shared: 共享缓存状态。in_memory: 标记该文件是否位于内存文件系统 (如 tmpfs) 中。append_lock: 追加写操作锁, 保证追加写的原子性。
其中 CachedFileShared 结构如下:
struct CachedFileShared {
page_cache: Mutex<LruCache<u32, PageCache>>,
evict_listeners: Mutex<LinkedList<EvictListenerAdapter>>,
}这里的 page_cache 就是 LRU 页缓存池, 并通过 evict_listeners
提供页面驱逐通知机制。
read_at 方法是 CachedFile 对外提供的读取入口, 根据 offset ( 起始读取字节偏
移 )、文件总长度、用户缓冲区剩余长度, 计算最终文件读取的字节区间。
提供从页表写回数据到用户空间, 并计算写入长度的闭包, 传入 with_pages 辅助函数。
impl CachedFile {
pub fn read_at(&self, dst: &mut impl BufMut, offset: u64) -> VfsResult<usize> {
let len = self.inner.len()?;
let end = (offset + dst.remaining_mut() as u64).min(len);
if end <= offset {
return Ok(0);
}
self.with_pages(
offset..end,
|_| Ok(0),
|read, page, range| {
let len = range.end - range.start;
dst.write(&page.data()[range.start..range.end])?;
Ok(read + len)
},
)
}
}with_pages 的逻辑就是, 遍历用户请求的页面, 逐个检查是否在缓存中, 如果不在就逐
个从 IO 设备读取数据。
impl CachedFile {
fn with_pages<T>(
&self,
range: Range<u64>,
page_initial: impl FnOnce(&FileNode) -> VfsResult<T>,
mut page_each: impl FnMut(T, &mut PageCache, Range<usize>) -> VfsResult<T>,
) -> VfsResult<T> {
let file = self.inner.entry().as_file()?;
let mut initial = page_initial(file)?;
let start_page = (range.start / PAGE_SIZE as u64) as u32;
let end_page = range.end.div_ceil(PAGE_SIZE as u64) as u32;
let mut page_offset = (range.start % PAGE_SIZE as u64) as usize;
for pn in start_page..end_page {
let page_start = pn as u64 * PAGE_SIZE as u64;
let mut guard = self.shared.page_cache.lock();
let page = self.page_or_insert(file, &mut guard, pn)?.0;
initial = page_each(
initial,
page,
page_offset..(range.end - page_start).min(PAGE_SIZE as u64) as usize,
)?;
page_offset = 0;
}
Ok(initial)
}
}我们的 readahead 修改逻辑就在这里, 不过由于 with_pages 已经被其他函数所依赖,
为了不对现有结构造成破坏, 我们将 readahead 相关的逻辑封装进子模块 readahead,
提供 Readahead trait 扩展 CachedFile, 暴露 with_prefetch 接口, 用于替换
with_pages, 并提供 feature 开关。
pub fn read_at(&self, dst: &mut impl BufMut, offset: u64) -> VfsResult<usize> {
let len = self.inner.len()?;
let end = (offset + dst.remaining_mut() as u64).min(len);
if end <= offset {
return Ok(0);
}
#[cfg(feature = "readahead")]
{
self.with_prefetch(offset..end, |read, page, range| {
let len = range.end - range.start;
dst.write(&page.data()[range.start..range.end])?;
Ok(read + len)
})
}
#[cfg(not(feature = "readahead"))]
{
self.with_pages(
offset..end,
|_| Ok(0),
|read, page, range| {
let len = range.end - range.start;
dst.write(&page.data()[range.start..range.end])?;
Ok(read + len)
},
)
}
}4.2 状态修改
pub struct CachedFile {
inner: Location,
shared: Arc<CachedFileShared>,
in_memory: bool,
append_lock: RwLock<()>,
#[cfg(feature = "readahead")]
ra_state: Mutex<readahead::ReadaheadState>,
}
pub struct ReadaheadState {
pub start_pn: u32,
pub size: u32,
pub async_size: u32,
pub prev_pn: u32,
pub max_pages: u32,
}向 CachedFile 新增 ra_state 状态, 用 Mutex 包裹提供内部可变性。
CachedFileShared 结构中:
struct CachedFileShared {
page_cache: Mutex<LruCache<u32, PageCache>>,
#[cfg(feature = "readahead")]
bounce_buffer: Mutex<Vec<u8>>,
#[cfg(feature = "readahead")]
pending_pool: Mutex<Vec<Arc<PendingPage>>>,
evict_listeners: Mutex<LinkedList<EvictListenerAdapter>>,
}向 PageCache 加入 pg_readahead 字段, 用于标记, PG_readahead; 加入
pending 字段, 包裹 axtask 提供的 WaitQueue, 用于实现唤醒通知。
pub struct PageCache {
addr: VirtAddr,
dirty: bool,
#[cfg(feature = "readahead")]
pg_readahead: bool,
#[cfg(feature = "readahead")]
pending: Option<Arc<PendingPage>>,
}
pub struct PendingPage {
wq: axtask::WaitQueue,
}4.3 readahead 策略
Readahead trait 接口如下:
pub(super) trait Readahead {
fn find_page_from_cache<'a>(
&self,
caches: &'a mut LruCache<u32, PageCache>,
pn: u32,
) -> Option<(&'a mut PageCache, Option<(u32, u32, u32)>)>;
fn with_prefetch(
&self,
range: Range<u64>,
write_buffer_callback: impl FnMut(usize, &mut PageCache, Range<usize>) -> VfsResult<usize>,
) -> VfsResult<usize>;
}find_page_from_cache 从 page cache 池中查找对应的页面, 如果在 page cache 池中
找到了对应页面, 还会检查是否有 PG_readahead flag, 如果有则会更新窗口状态并将
异步预读所需要的参数计算返回 (start, size, pg_readahead pn)。
impl Readahead for CachedFile {
fn find_page_from_cache<'a>(
&self,
caches: &'a mut LruCache<u32, PageCache>,
pn: u32,
) -> Option<(&'a mut PageCache, Option<(u32, u32, u32)>)> {
caches.get_mut(&pn).map(|cache| {
let mut new_window = None;
if cache.pg_readahead {
// find PG_readahead flag, clear the flag and prepare for async readahead
cache.pg_readahead = false;
let mut ra = self.ra_state.lock();
if ra.size > 0 {
ra.update_window_for_async();
new_window = Some((ra.start_pn, ra.size, ra.pg_readahead()));
}
}
(cache, new_window)
})
}
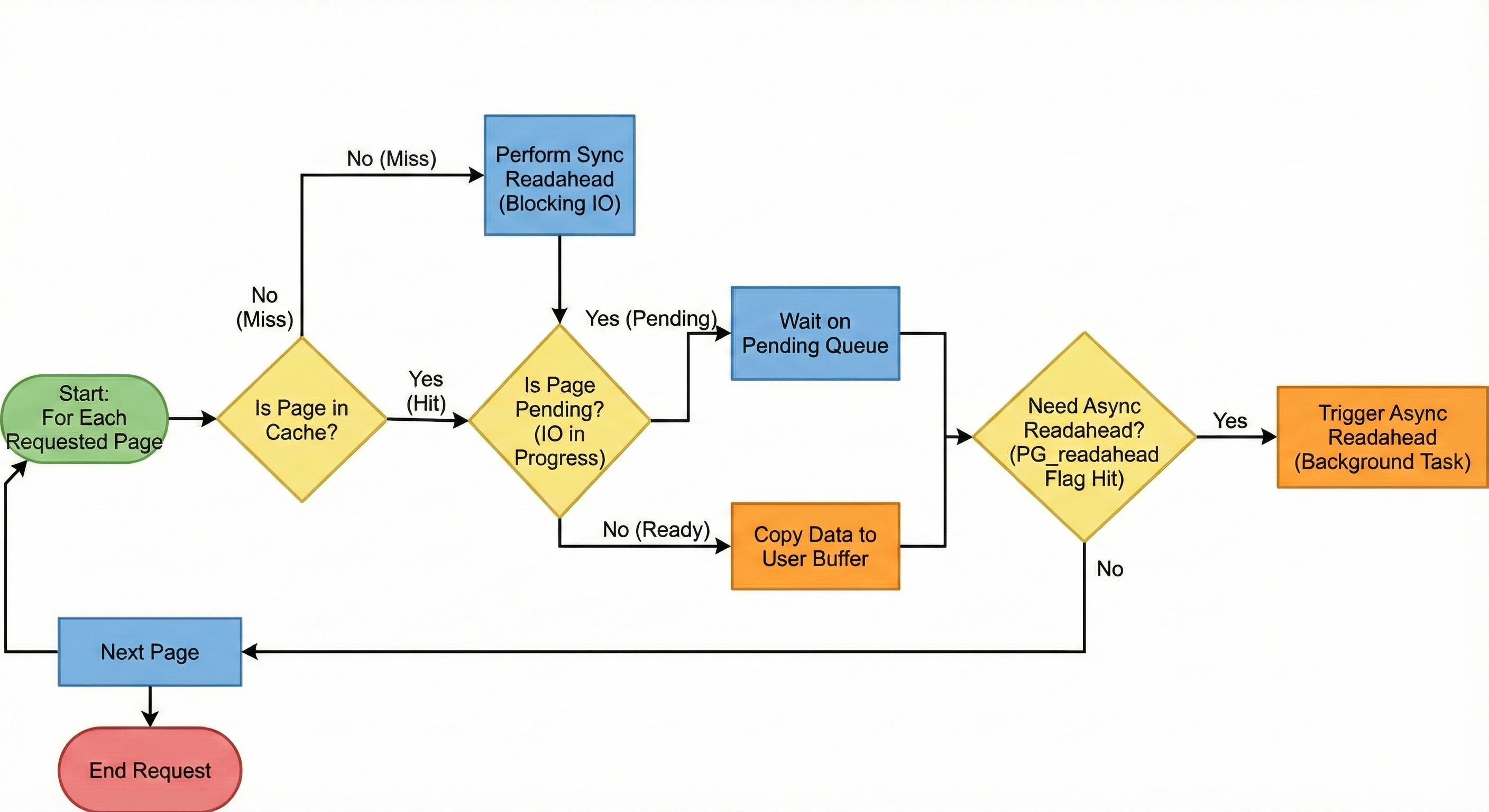
}with_prefetch 的结构与 with_pages 大体一致, 也是逐页面写回用户空间。不过增
加了 readahead 逻辑, 以及将 IO 请求聚合提交给设备。
整体采用决策与执行解耦的模式。对于每一个用户请求的页面, 先判断其读取策略, 在这
一步获取 ra_state 的锁, 一次性决策完, 而在接下来的具体执行阶段, 实现无
ra_state 锁。
impl Readahead for CachedFile {
fn with_prefetch(
&self,
range: Range<u64>,
mut write_buffer_callback: impl FnMut(usize, &mut PageCache, Range<usize>) -> VfsResult<usize>,
) -> VfsResult<usize> {
/*
same as `with_pages`
*/
for pn in start_page..end_page {
let page_start = pn as u64 * PAGE_SIZE as u64;
let mut pending = None;
let mut async_prefetch_info = None;
let mut cache_miss = false;
{
// make decision
let mut guard = self.shared.page_cache.lock();
if let Some((page, async_readahead)) = self.find_page_from_cache(&mut guard, pn) {
async_prefetch_info = async_readahead;
if page.pending.is_none() {
read_len = write_buffer_callback(
read_len,
page,
page_offset..(range.end - page_start).min(PAGE_SIZE as u64) as usize,
)?;
} else {
pending = page.pending.clone();
}
} else {
cache_miss = true;
}
}
if cache_miss {
/* do sync readahead logic */
continue;
}
if pending.is_some() {
/* pending, waiting for wake up */
}
if async_prefetch_info.is_some() {
/* trigger async readahead */
}
page_offset = 0;
}
// update `prev_pn` state after handling the whole user request
self.ra_state.lock().update_history(end_page - 1);
Ok(read_len)
}
}
4.4 聚合 IO
在 StarryOS 的 with_pages 方法中, 向底层 IO 设备读取的逻辑在 page_or_insert
方法中, 这是它的签名:
impl CachedFile {
fn page_or_insert<'a>(
&self,
file: &FileNode,
cache: &'a mut LruCache<u32, PageCache>,
pn: u32,
) -> VfsResult<(&'a mut PageCache, Option<(u32, PageCache)>)> {/* implementations */}
}表示从一个 IO 设备中读取 pn 页号对应的数据。
可以看到, cache 的类型是 &mut LruCache<u32, PageCache>, 这导致在此函数调用
期间, 上层 stack 一直持有 MutexGuard。这在逐页面提交 IO 的场景中是适用的, 可
是在我们需要批量读取的场景下, 这会导致持锁时间过长。
这是我们用于向底层 IO 设备提交读取请求, 将数据搬运到内核空间 (page cache) 的方 法签名:
pub fn io_submit(
cache_shared: &CachedFileShared,
file: &FileNode,
in_memory: bool,
start_pn: u32,
size: u32,
async_pg_pn: u32,
) -> VfsResult<()> {/* implementations */}我们将 io_submit 与 CachedFile 解耦了, 将所需要的状态都通过参数传入, 比如这
里的 in_memory, 在 page_or_insert 方法中是通过 self 获取的。start_pn,
size, async_pg_pn 对应上文提到的 find_page_from_cache 方法, 在判定为需要
异步预读时提供的数据。而 &mut LruCache 则通过 &CachedFileShared 传入, 以获
得对锁更细粒度的控制。
此外, 还可以快速复用 io_submit 实现异步预读 IO 提交:
pub fn async_prefetch(
cache_shared: Arc<CachedFileShared>,
file: Arc<dyn FileNodeOps>,
in_memory: bool,
start_pn: u32,
size: u32,
async_pg_pn: u32,
) -> VfsResult<()> {
let file = FileNode::new(file);
io_submit(&cache_shared, &file, in_memory, start_pn, size, async_pg_pn)
}参数都持有所有权, 可以方便的提交给调度器发起异步任务。
io_submit 的实现也采用决策先行, 执行在后的模式。
1. 待读取 pn 记录和 pending page 填充
先获取 page cache 锁, 扫描一遍待读取的页面是否已经存在 page cache 中。如果不存 在, 则将 pn 号记录, 并将 pending page 插入 page cache 池, 以防止其他线程进行重 复 IO。
对于 in_memory 的情况 (比如 tmpfs), page cache 本身就是数据来源, 不涉及 IO 设 备交互, 因此在扫描阶段就完成所有的数据搬运工作。
let mut owned: Vec<(u32, Arc<PendingPage>)> = Vec::with_capacity(size as usize);
{
let mut caches = cache_shared.page_cache.lock();
if in_memory {
// In-memory file: populate cache with zeros, no device IO.
for pn in start_pn..(start_pn + size) {
if let Some(page) = caches.get_mut(&pn) {
if pn == async_pg_pn {
page.pg_readahead = true;
}
continue;
}
let mut page = PageCache::new()?;
if pn == async_pg_pn {
page.pg_readahead = true;
}
page.data().fill(0);
caches.put(pn, page);
}
return Ok(());
}
// insert pending pages into lruCache
for pn in start_pn..(start_pn + size) {
if let Some(existing) = caches.get_mut(&pn) {
if pn == async_pg_pn {
existing.pg_readahead = true;
}
continue;
}
if caches.len() == caches.cap().get()
&& let Some((evict_pn, mut evict_page)) = caches.pop_lru()
&& evict_page.pending.is_none()
{
// Cache is full: evict a non-pending page. Pending pages must not be evicted,
// otherwise waiters may observe missing pages / incorrect data.
drop(caches);
cache_shared.evict_cache(file, evict_pn, &mut evict_page)?;
caches = cache_shared.page_cache.lock();
}
let pending = cache_shared.alloc_pending();
let mut page = PageCache::new_pending(pending.clone())?;
if async_pg_pn == pn {
page.pg_readahead = true;
}
caches.put(pn, page);
owned.push((pn, pending));
}
}2. IO 读取
分配 bounce buffer, 优先从 cache_shared 中的缓冲区获取。这里采用非阻塞获取,
如果遇到锁竞争, 马上停止等待, 重新在堆上分配一块。由于bounce buffer 马上要写
入从 IO 设备获取的数据, 因此没有必要初始化置 0, 在这里用 unsafe 特性, 分配未初
始化的内存来提高性能。
unsafe {
if let Some(mut guard) = cache_shared.bounce_buffer.try_lock() {
// Fast path: reuse shared buffer (no allocation).
let bounce_buffer = guard
.as_mut_slice()
.get_unchecked_mut(0..span_pages * PAGE_SIZE);
io_worker(bounce_buffer)
} else {
// Contended: keep memory bounded but avoid blocking behind other IO.
let mut bounce_buffer = Vec::with_capacity(span_pages * PAGE_SIZE);
bounce_buffer.set_len(span_pages * PAGE_SIZE);
io_worker(bounce_buffer.as_mut_slice())
}
}?;这里通过 io_worker 闭包来执行将数据从底层设备搬运到 bounce_buffer, 并拷贝到
page cache 的 pending page 中的工作。
let io_worker = |bounce_buffer: &mut [u8]| -> VfsResult<()> {
file.read_at(bounce_buffer, first_pn as u64 * PAGE_SIZE as u64)?;
let mut caches = cache_shared.page_cache.lock();
for &(pn, _) in &owned {
let offset = (pn - first_pn) as usize * PAGE_SIZE;
if let Some(page) = caches.get_mut(&pn) {
// Pending page is found in the lruCache, which is the most case
// page.pending.reset_ok();
page.pending = None;
page.data()
.copy_from_slice(&bounce_buffer[offset..offset + PAGE_SIZE]);
} else {
warn!("Pending page not found in cache during readahead.");
// pending page had been evicted perhaps
let mut page = PageCache::new()?;
if pn == async_pg_pn {
page.pg_readahead = true;
}
page.data()
.copy_from_slice(&bounce_buffer[offset..offset + PAGE_SIZE]);
if caches.len() == caches.cap().get()
&& let Some((evict_pn, mut evict_page)) = caches.pop_lru()
{
drop(caches);
cache_shared.evict_cache(file, evict_pn, &mut evict_page)?;
caches = cache_shared.page_cache.lock();
}
caches.put(pn, page);
};
}
Ok(())
};在涉及与 IO 设备的交互过程中, page cache 的锁都没有持有, 因为这一步是耗时的, 如 果持锁会导致持锁过长。
5. 问题和展望
5.1 调度开销与异步预读的悖论
在性能测试中,我们发现了一个反直觉的现象:在某些负载下,开启异步预读(Async Readahead)后的性能提升并不明显,甚至在极端情况下不如纯同步预读。
经过深入分析,我们发现瓶颈转移到了 任务调度(Task Scheduling) 上。目前 StarryOS 基于 ArceOS 的协作式调度器,在处理高频的短任务(如频繁触发的异步预读协 程)时,上下文切换(Context Switch)的开销变得不可忽视。
当 IO 设备(如 NVMe SSD 或高性能 VirtIO)的速度足够快,而每次 IO 请求的数据量又 较小时,CPU 可能会花费更多的时间在“切换到后台预读任务”和“切换回前台应用”之间, 而不是真正执行 IO 逻辑。这种 调度开销(Scheduling Overhead) 抵消了流水线带 来的并行收益。
未来方向:
- 优化调度器路径,减少协程切换的指令周期。
- 探索 Batch Scheduling,将多个小的预读任务合并为一个大的后台任务执行。
5.2 零拷贝的最后一块拼图:Scatter-Gather DMA
虽然引入 Bounce Buffer 解决了驱动交互次数过多的问题,但它本质上仍然引入了一次额 外的内存拷贝(Bounce Buffer -> Page Cache)。对于内存带宽敏感型应用,这依然是一 个瓶颈。
真正的零拷贝(Zero Copy)预读需要驱动层支持 Scatter-Gather DMA。即允许文件 系统层构建一个包含多个物理不连续页面的描述符链(Descriptor Chain),直接传递给 VirtIO 驱动。驱动程序通知硬件直接将数据 DMA 到这些离散的物理页中,从而完全消除 CPU 参与的数据拷贝。
这需要对现有的 axdriver 和 virtio 驱动进行重构,支持传递 IoVec 或类似的离
散内存结构。
5.3 从轮询到中断:真正的异步 IO
目前 StarryOS 的 VirtIO 驱动仍采用 轮询(Polling) 模式等待 IO 完成。这意味 着即使在等待 IO 时,CPU 也在空转检查状态位,或者依赖调度器轮询。
虽然预读机制通过批处理减少了提交端的开销,但完成端的轮询依然占用宝贵的 CPU 周期, 且无法让 CPU 进入低功耗状态。
未来计划:
- 实现基于 中断(Interrupt) 的异步通知机制。
- 配合 Rust 的
Waker/Poll异步原语,实现真正的事件驱动 IO。当 IO 完成时,硬件 中断唤醒对应的Future,从而实现真正的零阻塞。